Problem 1
Step-1
The disk scheduling other than FCFS scheduling is useful in a single user environment.
• In a single-user environment, only one process will be executing.
• Requests for I/O devices will arrive only from single process.
• Therefore, the queues for I/O devices will be usually empty.
• In such case, the FCFS scheduling an economical method of disk scheduling.
• However, LOOK scheduling algorithm is a better and easy method for disk scheduling.
• It is easy to program a LOOK scheduling algorithm. In addition, it will give much better performance when multiple processes are performing I/O operations concurrently.
Problem 2
Step-1
SSTF Scheduling:
In order to maximize the throughput, the following should be done in Shortest Seek Time First (SSTF) Scheduling.
• To have the service request possible per unit time.
• To maximize the response meantime that is to provide the response rapidly to most of the interactive users.
• To minimize the response time variance that is to provide the predictability.
Step-2
SSTF scheduling algorithm is basically biased towards the middle of the cylinders same as the SCAN algorithm.
As in the SSTF algorithm, the closest value of cylinder is selected first, then it is followed by the middle cylinder and at last, the end of the cylinder disk is served.
The head of the disk do tend to be placed away from the disk edge since the center of the disk is probably the location that consists of the smallest average distance to the other tracks.
Step-3
Thus, due to this the current position of the head divide the cylinders of the disk into two groups.
• If some new request arrives and the head is not in the center, thus the new request switches into the group that basically includes the center of the disk.
• Thus, the head of the disk moves in its direction.
Problem 3
Step-1
A timing problem arises: the program that would do the latency-time orderingneeds to know the number of the sector that would be underneath the head at the timeof I/O service. This information would have to come immediately before servicing theI/O request in order to be accurate. This would require extra communication with theperipheral which would take time, canceling some of the benefit.
The disk scheduling algorithms consider only seek times because for modern disks, the rotational latency can be nearly as large as average seek time. It is difficult for the operating system to schedule for improved rotational latency because modern disks do not disclose the physical location of logical blocks. The mapping between logical blocks and physical locations is very complex.
We would optimize both seek time and rotational latency by modifying the implementation of disk-scheduling algorithms (such as SSTF, SCAN, and C-SCAN ) as the controller hardware built into the disk drive. If the operating system sends a batch of requests to the controller, the controller can queue them and then schedule them to improve both the seek time and rotational latency.
Problem 4
Step-1
• Computer system could only perform at the slowest possible speed.
• The controllers of the disks and the disks are much more frequent bottleneck in the todays modern systems as the individual performance of such systems couldn’t keep with the system bus and the CPU’s.
• By balancing I/O among disks and controllers, neither an individual disk nor a controller is overwhelmed, so that bottleneck is avoided.
Problem 5
Step-1
2481-12-24E SA: 8683
SR: 4578
Various tradeoffs involved in rereading code pages from the file system versus swap space :
1. It is more efficient to reread a page from the file system than first write it to swap space and then reread it from swap space when page is selected for page-out by virtual memory.
2. It is efficient to write a page to swap space and reread it from there when the page is forced out of physical memory rather than when the virtual memory page is first created.
3. Swap space is only used as a backing store for pages of anonymous memory, which includes memory allocated for the stack, heap and uninitialized data of a process.
4. Swap space is used for regions of memory shared by several processes.
5. Swap space is limited compared to file system space. So, it is difficult to store both code and data pages in swap space.
Problem 6
Step-1
Truly Stable Storage
Yes , a truly stable storage is one that will never lose the data. Thus, the technique to maintain the multiple copies of the data is called as the stable storage.
Next, if one copy of the data is destroyed then some other copy of the data is available for the usage. But all copies of the data could be destroyed if an uncertain large disaster arrives.
Problem 7
Step-1
Given data :
| Media | Streaming Transfer Rate | Latency |
|---|---|---|
| Level-2 cache | 800 MB/sec | 8 nano seconds |
| Main memory | 8 MB/sec | 60 nano seconds |
| Magnetic disk | 5 MB/sec | 15 milli seconds |
| Tape drive | 2 MB/sec | 60 seconds |
Step-2
a. Calculate the Effective Transfer Rate (ETR), the formulas for finding effective transfer rate is given below:

Where 
Step-3
(1) For 512 bytes, the effective transfer rate is calculated as shown in below:

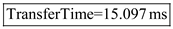
Step-4


Step-5
(2) For 8 kilobytes, the effective transfer rate is calculated as shown in below:

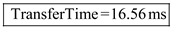
Step-6

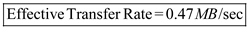
(3)
Step-7
For 1 megabyte, the effective transfer rate is calculated as shown in below:


Step-8

Step-9
(4) For 16 megabytes, the effective transfer rate is calculated as shown in below:

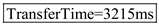
Step-10
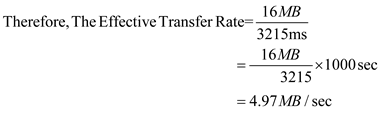

Step-11
b. Calculation the utilization of the disk drive for each of the four transfer sizes. The formula for utilization of disk drive device is given below:

Step-12
(1) For 512 bytes, Utilization of disk drive device is calculated as shown in below:


Step-13
(2) For 8kilobytes,Utilization of disk drive device is calculated as shown in below:
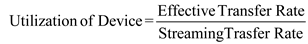


(3) For 1megabytes,Utilization of disk drive device is calculated as shown in below:
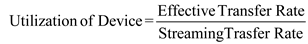


Step-14
(4) For 16megabytes, Utilization of disk drive device is calculated as shown in below:
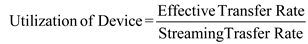


Step-15
C.As given in the question, utilization of 25 percent (0.25) is acceptable. We know that
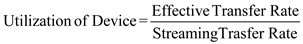
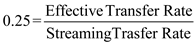
Where Streaming Transfer Rate=5MB

Step-16
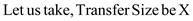
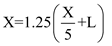
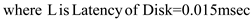
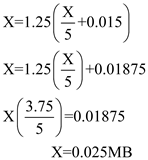
Step-17
d.A disk is a random-access device for transfers larger than k-bytes (where k >block size of disk device) and is a sequential access device for smaller transfers.
Step-18
e. computing the minimum transfer sizes for acceptable utilization of cache memory:
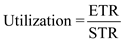
We know that the acceptable utilization is 0.25 or more is accepted.
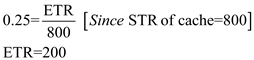
Step-19

Step-20

Therefore, the minimum transfer size for acceptable utilization of cache memory is 2.08 bytes.
Computing the minimum transfer sizes for acceptable utilization of main memory:
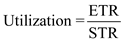
We know that the acceptable utilization is 0.25 or more is accepted.
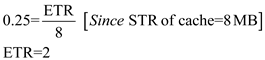
Step-21

Step-22

Therefore, the minimum transfer size for acceptable utilization of main memory is 1.68 bytes.
Step-23
Computing the minimum transfer sizes for acceptable utilization of tape device:
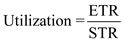
We know that the acceptable utilization is 0.25 or more is accepted.
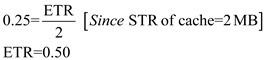
Step-24

Step-25

Therefore, the minimum transfer size for acceptable utilization of tape device is 40 MB.
Step-26
f. It depends on what situation we are using the device. If the device is access the records at some fixed length then the device is random access. If the device is accessing the same records sequentially then it is called sequential access.
Problem 8
Step-1
RAID level 0 – it refers to disk arrays with striping at the level of blocks but without any redundancy. Since redundancy is not there any data lost can’t be overcomed. So, it is used in high-performance applications where data loss is not critical.
RAID level 1 – It refers to disk mirroring. So, it is popular for applications that require high reliability with fast recovery.
Mirroring provides high reliability, but it is expensive. Stripping provides high data transfer rate, but it does not improve reliability.
Problem 9
Step-1
a) None of the disk – scheduling disciplines, except FCFS, is truly fair.
This assertion is true because it is based on first – come, first – served it does not provide the fastest services. It is because as this algorithm serves the request that come first it won’t give any priority for new requests though they are less spaced. Thus no starvation.
Step-2
b) SCAN is modified to C-SCAN i.e., circular SCAN(C-SCAN). It is designed to provide a more uniform wait time. It essentially treats the cylinders as a circular list that wraps around from the final cylinder to the first one.
Step-3
c) Fairness is an important goal in a time-sharing system because it increases the performance of the system. The performance depends heavily on the number and type of requests. Also in order to serve all the requests within less time with respect to newly arriving requests.
Step-4
d) Operating system is unfair in servicing I/O request.
(i) Demand paging may take priority over application I/O.
(ii) If the cache is running out of the pages, then writes are more urgent than reads.
(iii) It guarantees the order of a set of disk writes to make the file system robust in the face of system crashes.
Problem 10
Step-1
SSDs stands for Solid State Disks. This is a non-volatile memory and it is working just like a hard drive. SSDs**** have no head to move. SSDs have no seek time and latency. So, they are very fast and chomps less power.
• There are many disk scheduling algorithms are there such as FCFS , SSTF,SCAN,C-SCAN,LOOK,C-LOOK. The different disk scheduling algorithms are used to minimize the head movements.
• FCFS stands for First come First Serve. This is a very simple scheduling algorithm. It performs according to the request order. There is no starvation found here.
• The other scheduling algorithms are based on seek time, variance, latency. Though, SSDs have no head, seek time and latency, it uses the simplest general purpose scheduling algorithm FCFS.
If SSDs will use another disk scheduling algorithm, Then, its performance may decrease. So, FCFS is the right scheduling algorithm for SSDs**.**
Problem 11
Step-1
In this problem the given data are as follows:-
Number of cylinders:-5000
Currently head position:-2150
Queue: -2069, 1212,2296,2800,544,1618,356,1523,4965,3681
Step-2
FCFS Disk Scheduling algorithm:- In FCFS is an operating system process scheduling algorithm, the requests are managed by the order of their arrival. in other words, First come, first serve basis.
Consider the following diagram of FCFS disc scheduling:
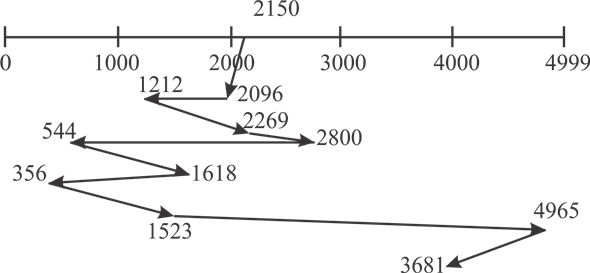
Distance of head movement in FCFS disk scheduling algorithm is as follows:

Hence, the toatal distance moved= 13011cycles.
Step-3
SSTF disk scheduling algorithm:- In SSTF disk scheduling algorithm, request is selected with the minimum seek time from the current position of head.
Consider the following diagram of SSTF disc scheduling:
**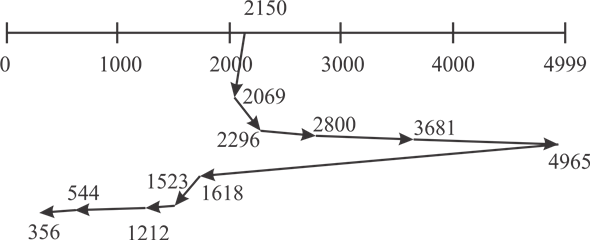 **
**
Distance of head movement in SSTF disk scheduling algorithm is as follows:-

Hence, the toatal distance moved=7586cycles.
Step-4
SCAN disk scheduling algorithm:- This algorithm is also known as an Elavator algorithm. In which, the disc arm is started from one of the disk end and move towards the other end and servicing the requests until it approaches to the other end of the disk. At the end the movement, head is reversed and continue the services.
Consider the following diagram of SCAN disc scheduling:
**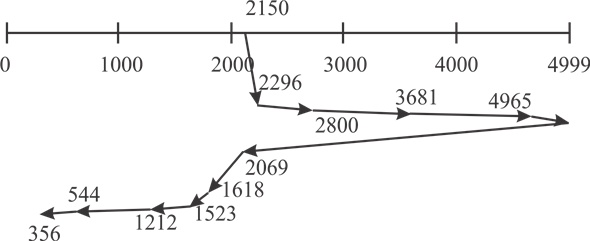 **
**

Hence, the toatal distance moved=7492cycles.
Step-5
C-SCAN disk scheduling algorithm:- In C-SCAN disk scheduling algorithm, the disc arm is started from one of the disk end and move towards the other end and servicing the requests until it approaches to the other end of the disk.
At the end of the movement, the head immediately returns to the beginning of the disk and continue the services.
Consider the following diagram of CSCAN disc scheduling:
**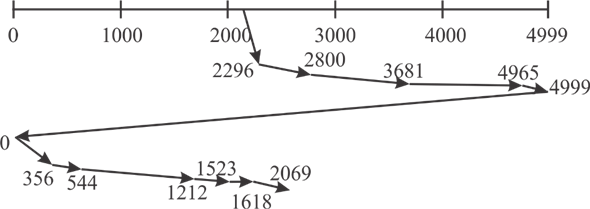 **
**
Distance of head movement in C-SCAN disk scheduling algorithm is as follows:-
 Hence, the toatal distance moved= 9917 cycles.
Hence, the toatal distance moved= 9917 cycles.
Step-6
e.
LOOK disk scheduling algorithm: **** LOOK is a disk scheduling algorithm used to determine the order in which new disk read and write requests are processed.
Consider the following diagram of LOOK disc scheduling:
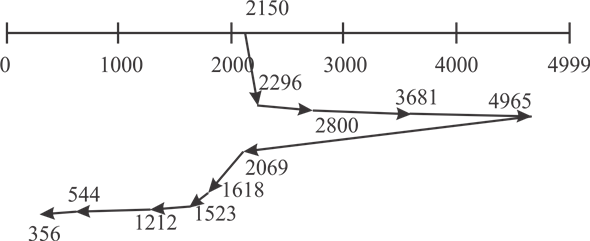
Distance of head movement in LOOK disk scheduling algorithm is as follows:-
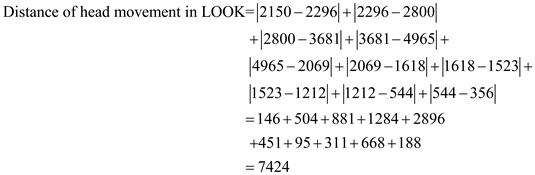
Hence, the toatal distance moved= 7424 cycles
Step-7
f.
C-LOOK disk scheduling algorithm:
Consider the following diagram of C-LOOK disc scheduling:
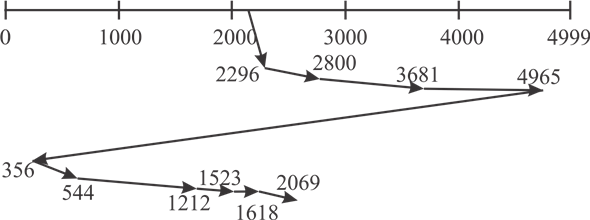
Distance of head movement in C-LOOK disk scheduling algorithm is as follows:
 Hence, the toatal distance moved=9137 cycles
Hence, the toatal distance moved=9137 cycles
Problem 12
Step-1
a)
According to the Elementary physics it is found that

where d = Distance
a =acceleration
t =Time
Now, solving the above equation, user obtained:

As it is already known that the acceleration is constant. Therefore, the above expression is 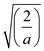 is also constant.
is also constant.
Hence, 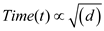
Step-2
b)
Given Data is as follows:-
Total distance d=4999
Time t=18 milli second
Now from the above equation  the acceleration can be find out
the acceleration can be find out

Now, the resulting equation is,
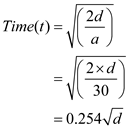
Hence, 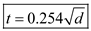
Step-3
c)
The Seek time is defined as the time required for the movement of the disk arm to the required track. Rotational delay or latency is the time it takes for the starting of the required sector to reach the head.
The seek time for all the scheduling algorithm is as follows:-
FCFS
=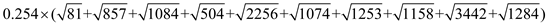
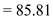
Hence, for FCFS the seek time is 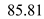 .
.
SSTF = 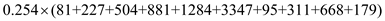
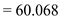
Hence, for SSTF the seek time is 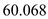 .
.
SCAN 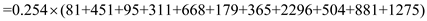
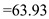
Hence, for SCAN the seek time is 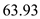 .
.
CSCAN 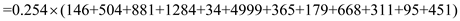
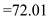
Hence, for C-SCAN the seek time is 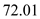 .
.
LOOK 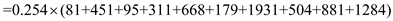
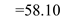
Hence, for LOOK the seek time is 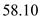 .
.
C-LOOK 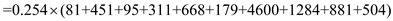
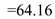
Hence, for C-LOOK the seek time is 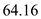 .
.
Now, from the above result it can be said that**** Seek time is minimum in LOOK disk scheduling algorithm. So LOOK disk scheduling algorithms is faster .
Step-4
d) speedup of fastest schedule over FCFS is as follows:- as the seek time of the FCFS is 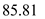 and the seek time for LOOK is
and the seek time for LOOK is 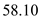 then;
then;
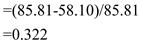
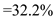 faster.
faster.
Problem 13
Step-1
The data given in the problem are:-
Disk rotates =7200 revolution per minute.
So, in one second the disk rotates= 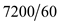
=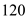 rotations.
rotations.
Now, one rotation will take = 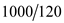 ms
ms
= 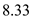 ms
ms
From the definition of latency, it is aready known that latency is half of the rotation. Therefore, Latency = half of the rotation
=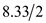
=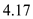 ms
ms
Hence, the average rotational time latency of the disc drive is 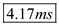
Step-2
According to the equation t is given as:
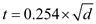
Now from the above part as described, the value of 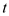 is equals to
is equals to 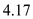 ms. Hence, after putting this value in the equation which is given above, the value obtained is :
ms. Hence, after putting this value in the equation which is given above, the value obtained is :
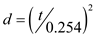
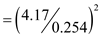
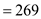 cylinders
cylinders
Hence, the Distance covered in the time 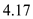 is equals to
is equals to 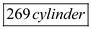 .
.
Problem 14
Step-1
The advantages of using SSDs over magnetic disk drives are given below:
• Data Access is faster on SSDs compared to the hard disk drives.
• It uses flash memory and don’t use any moving head. So, it is more consistent and provide enhanced performance than hard disk drives.
• It consumes less power.
• The Solid State Disks have no moving head. So, this is less noisy. Hard disk drives are somewhat noisy as they have read/write moving head.
• It generates less heat than that of the hard disk drives. So. Its lifespan is more and will not damage.
• It has no magnetic parts. So, it is not affected by magnetism, but hard disk drives has magnetic parts. So some time data may lost due to magnetism effect.
Step-2
The disadvantages of using SSDs over magnetic disk drives are given below:
• It has limited storage capacity than that of HDD.
• This is very expensive as comapared to magnetic disk drives.
• If SSDs are severely used then data maintenance capacity will be minimized.
Problem 15
Step-1
In SCAN algorithm, the disk arm starts at one end of the disk, and moves towards the other end, servicing requests as it reaches each cylinder, until it gets to the other end of the disk. At the other end, the direction of head movement is reversed, and servicing continues. The head continuously scans back and forth across the disk.
C-SCAN is designed for more uniform wait. Like SCAN, C-SCAN moves the head from one end of the disk to the other, servicing requests along the way. When the head reaches the other end, it immediately returns to the beginning of the disk, without servicing any requests on return trip. It treats the cylinder as a circular list that wraps around from the final cylinder to the first one.
C-SCAN has an average response time just a few percent higher than SCAN but C_SCAN has an significantly lower variance in response time for medium and heavy workloads. The intuitive reason for this variance is that SCAN tend to favor requests in middle cylinders where as C-versions do not have this imbalance.
These algorithms do not schedule to improve rotational latency; therefore, as seek times decrease relative to rotational latency, the performance differences between the algorithms decrease.
Problem 16
Step-1
Shortest Seek Time First(SSTF): It select the request that is nearest to the current head position.
Ageing is the mechanism where the priority of the process increases gradually on the basis of its waiting time. If a process does not receive CPU for a long time then aging will occur.
Step-2
• Shortest Seek Time First is the best scheduling algorithm as it serves the request that are nearer to the current head position and would be able to take the advantage of the given situation.
• Other scheduling algorithm like first come first serve (FCFS) could cause head movement that are unnecessary when frequently visited cylinder were placed far apart from each other.
Step-3
• One of the solution can be to place thehot spot in or near the middle of the disk, so that it can be nearer to all the data on average cases.
• Modified shortest seek time first scheduling algorithm can be used to avert starvation.
• Also, some policy can be added to let the operating system generate a seek to the hot spot whenever the disk sits idle for more than 50ms, as the next request might be there.
• This helps in making the operating system busy. Even this helps in preventing ageing for the older request.
• With the help of Hotspot each and every request gets an equal importance.
Problem 17
Step-1
RAID level 5 – It is also called as block inter leaved distributed parity, differs from level 4 by spreading data and parity among all N + 1 disks, rather than storing data in N disks and parity in one disk.
A parity block cannot store parity for blocks in the same disks, because a disk failure would result in loss of data as well as of parity and hence the loss would not be recoverable.
Step-2
RAID 5 avoids the potential over use of a single parity disk that can occur with RAID 4. RAID 5 is most common parity system.
a)
In order to perform a write operation, parity bits must be changed. Process the following steps:
-
Read the parity block.
-
Write the new data.
-
XOR the old data with the new data.
-
Read the old parity from the array.
-
Compute the parity for the next set of blocks.
-
Write the updated parity back to the array.
Step-3
b) In order to perform a write to seven continuous blocks of data, the following are the steps:
-
Read the old data.
-
Write the new data.
-
XOR the old data with the new data.
-
Read the old parity from the array for the seven blocks.
-
Compute the parity for the next set of blocks.
-
write the updated parity back to the array (for seven blocks).
Problem 18
Step-1
RAID 1 performance can actually be slightly better than a standard disk implementation for read operations. Because the contents of both drives are identical, the array management software is free to select the drive which can most quickly satisfy the request.
Since RAID 5 systems work with independent spindles, random I/O is naturally load balanced, making them capable of read performance approaching that of RAID\x110, but with much better reliability. RAID 5 requires only one additional drive to add parity protection, resulting in similar economics.
Problem 19
Step-1
RAID level 1 is popular for applications that require high reliability with fast recovery. Due to RAID 1’s high space overhead, RAID 5 is often preferred for staring large volumes of data. Any write to RAID level 1 requires operations twice in order to modify actual and mirrored data. In RAID level 5, no need.
Problem 20
Step-1
Rebuilding is earliest for RAID 1, since data can be copied from one to another disk, where as rebuild time can be in hours for RAID 5 rebuilds of large disk sets.
RAID level 1 is for applications that require high reliability with fast recovery. Due to high space overhead at RAID 1, RAID level 5 is often preferred for storing large volumes of data except for multimedia database storage and video applications. Where as RAID level 1 is suitable for small database where reliability is more important.
Problem 21
Step-1
300-12-14E

a) Disk drives = 1,000
Each has 750,000 hour MTBF
Mean time for disks drives = 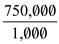
= 750 hrs per failure about 31 days or once per month
Step-2
b) 1: 000 chances of dying between ages 20 & 21 years.
Human-hours per failure is 8760(hrs in a year) divided by 0.001 failure, giving a value of about 8,760,000 hours for the MTBF. 8760000 hours equals 1000 years. This tells us nothing about the expected lifetime of a person of age 20.
Step-3
c) The MTBF tells nothing about the expected lifetime. Hard disk drives are generally designed to have a lifetime of 5 years. If such a drive truly has a million-hour MTBF, it is very unlikely that the drive will fail during its expected lifetime.
Problem 22
Step-1
Sector sparing can cause an extra track switch and rotational latency, causing an unlucky request to require an extra 8ms of time. Sector slipping has less impact during future reading, but at sector remapping time it can require the reading and writing of an entire track’s worth of data to slip the sectors past the bad spot.
Problem 23
Step-1
An Operating System (OS) does the following things while allocating the blocks:
• If an Operating System has more information regarding to the physical location of blocks on the disks, then it could allocate the blocks for a file geometrically which are close by on the disk.
• OS allocates a first block of data to the disk by the above procedure, then allocates the second block of data to the same cylinder of the disk but the surface is different. Because, the disk is rotationally optimal.
Step-2
Performance improvement of the file-system:
The OS allocates blocks of data on the same cylinder of disk with different surfaces because, the disk is rotationally optimal place.
As the OS allocates blocks of data on the same cylinder, the data can be accessed easily. Therefore, the cost is minimized, and the file-system performance is improved.
Problem 24
Step-1
FCFS Scheduling algorithm: In FCFS is an operating system process scheduling algorithm, the requests are managed by the order of their arrival. in other words, First come, first serve basis.
Consider the following program:
int main**()**
{
// Initialize the variables
int Que**[** 20**],** n**,** Head**,** a**,** b**,** Seek_Time**=** 0**,** Maximum**,** Difference**;**
float Avg**;**
//Enter the maximum range of the disk
printf**(** “Enter the maximum range of disk”);
scanf**(** “%d”, &Maximum);
//Enter the maximum size of the request queue.
printf**(** “Enter the size of Request Queue”);
scanf**(** “%d”, &n);
//Enter the request in the queue.
printf**(** “Enter the request in queue”);
//For() loop is used to iterate through the queue.
for**(** a**=** 1**;** a**< =n;** a**++)**
{
scanf**(** “%d”, &Que[ a**]);**
}
//Enter the first head position.
printf**(** “enter the first head position”);
scanf**(** “%d”, &Head);
//Initialize the head queue to zero
Que**[** 0**]=** Head**;**
//For() loop is used to take the absolute value of
//the difference between the consecutive queue.
for**(** b**=** 0**;** b**< =n-** 1**;** b**++)**
{
Difference**=** abs**(** Que**[** b**+** 1**]-** Que**[** b**]);**
Seek_Time**+=** Difference**;**
printf**(** “Head move is from %d to %d with Seek_Time
%d\n”, Que**[** b**],** Que**[** b**+** 1**],** Difference**);**
}
//Print the total seek time
printf**(** “total seek time is%d\n”, Seek_Time**);**
//calculate the average seek time
Avg**=** Seek_Time**/(** float**)** n**;**
printf**(** “avrage seek time is %f\n”, Avg**);**
getch**();**
}
Step-2
Output:
Enter the maximum range of disk180
Enter the size of Request Queue8
Enter the request in queue78
90
87
56
34
66
42
23
enter the first head position130
Head move is from 130 to 78 with Seek_Time 52
Head move is from 78 to 90 with Seek_Time 12
Head move is from 90 to 87 with Seek_Time 3
Head move is from 87 to 56 with Seek_Time 31
Head move is from 56 to 34 with Seek_Time 22
Head move is from 34 to 66 with Seek_Time 32
Head move is from 66 to 42 with Seek_Time 24
Head move is from 42 to 23 with Seek_Time 19
total seek time is195
avrage seek time is 24.375000
SSTF disk scheduling algorithm: In SSTF disk scheduling algorithm, request is selected with the minimum seek time from the current position of head.
Consider the following program:
void main()
{
//Initialize the variables.
int Queue[130],t[30],Head,Seek_Time=0,n,a,b,temp;
float Avg;
//Enter the size of the queue.
printf(“Enter the size of Queue\t”);
scanf(“%d”,&n;);
//Enter the initial head position
printf(“Enter the initial head position\t”);
scanf(“%d”,&Head;);
//Enter the request in queue.
printf(“Enter the request in Queue\t”);
//Fro() loop is used to take the value of the queue.
for(a=0;a
{
scanf(“%d”,&Queue;[a]);
}
for(a=1;a
{
t[a]=abs(Head-Queue[a]);
}
//Nested for() loop is used to copy.
for(a=0;a
{
for(b=a+1;b
{
if(t[a]>t[b])
{
temp=t[a];
t[a]=t[b];
t[b]=temp;
temp=Queue[a];
Queue[a]=Queue[b];
Queue[b]=temp;
}
}
}
for(a=1;a
{
Seek_Time=Seek_Time+abs(Head-Queue[a]);
Head=Queue[a];
}
printf(“\nTotal Seek Time is%d\t”,Seek_Time);
//Calculate the average seek time
Avg=Seek_Time/(float)n;
printf(“\nAverage Seek Time is %f\t”,Avg);
getch();
}
Step-3
Sample Output:
Enter the size of Queue 8
Enter the initial head position 1234
Enter the request in Queue 456
789
1456
2000
1500
900
500
678
Total Seek Time is2766
Average Seek Time is 345.750000
SCAN disk scheduling algorithm: :- This algorithm is also known as an Elavator algorithm. In which, the disc arm is started from one of the disk end and move towards the other end and servicing the requests until it approaches to the other end of the disk. At the end the movement, head is reversed and continue the services.
Consider the following program**:**
int main**()**
{
//Initialize the variables.
int a**[** 20**],** b**[** 20**],** n**,** i**,** j**,** temp**,** pre**,** seek_time**,** max**,** x**,** t**=** 0**;**
//Enter the head position
printf**(** “Enter head pointer position:”);
scanf**(** “%d”, &a[ 0**]);**
//Initialize the seek_time as the head of the queue.
seek_time**=** a**[** 0**];**
//Enter the previous head position.
printf**(** “\nEnter previous head position:”);
scanf**(** “%d”, &pre);
//Enter the queue size.
printf**(** “\nEnter Queue size:”);
scanf**(** “%d”, &max);
//Enter the number of request.
printf**(** “\nEnter number of Requests:”);
scanf**(** “%d”, &n);
//Enter the request in the queue.
printf**(** “\nEnter requests in queue”);
//for() loop is used to take the input in the queue.
for**(** i**=** 1**;** i**< =n;** i**++)**
{
scanf**(** “%d”, &a[ i**]);**
}
a**[** n**+** 1**]=** max**;**
a**[** n**+** 2**]=** 0**;**
//Nested loop is used to swap the values.
for**(** i**=** n**+** 1**;** i**>=** 0**;** i**—)**
{
for**(** j**=** 0**;** j**< =i;** j**++)**
{
//check if a[j]>a[j+1]
if**(** a**[** j**]>** a**[** j**+** 1**])**
{
//swapping performed here.
temp**=** a**[** j**];**
a**[** j**]=** a**[** j**+** 1**];**
a**[** j**+** 1**]=** temp**;**
}
}
}
//check for seek_time==a[i]
for**(** i**=** 1**;** i**< =n+** 1**;** i**++)**
{
if**(** seek_time**==** a**[** i**])**
x**=** i**;**
}
j**=** 0**;**
c//check if seek_time is less than pre
if**(** seek_time**<** pre**)**
{
for**(** i**=** x**;** i**>** 0**;** i**—)**
{
t**+=(** a**[** i**]-** a**[** i**-** 1**]);**
b**[** j**++]=** a**[** i**];**
}
t**+=** a**[** x**+** 1**]-** a**[** 0**];**
b**[** j**++]=** a**[** 0**];**
for**(** i**=** x**+** 1**;** i**<** n**+** 1**;** i**++)**
{
t**+=(** a**[** i**+** 1**]-** a**[** i**]);**
b**[** j**++]=** a**[** i**];**
}
b**[** j**++]=** a**[** i**];**
}
// else exccute this part
else
{
for**(** i**=** x**;** i**<** n**+** 2**;** i**++)**
{
t**+=(** a**[** i**+** 1**]-** a**[** i**]);**
b**[** j**++]=** a**[** i**];**
}
t**+=** a**[** n**+** 2**]-** a**[** x**-** 1**];**
b**[** j**++]=** a**[** n**+** 2**];**
for**(** i**=** x**-** 1**;** i**>** 1**;** i**—)**
{
t**+=(** a**[** i**]-** a**[** i**-** 1**]);**
b**[** j**++]=** a**[** i**];**
}
b**[** j**++]=** a**[** i**];**
}
printf**(** “\nRequests order:”);
for**(** i**=** 0**;** i**< =n+** 1**;** i**++)**
printf**(** “\t%d”, b**[** i**]);**
printf**(** “\nTotal Head Movement:%d”, t**);**
getch**();**
}
Step-4
Sample Output:
Enter head pointer position:122
Enter previous head position:90
Enter Queue size:199
Enter number of Requests:6
Enter requests in queue33
49
97
123
156
30
Requests order: 122 123 156 199 97 49 33 30
Total Head Movement:246
Step-5
C-SCAN disk scheduling algorithm: : In C-SCAN disk scheduling algorithm, the disc arm is started from one of the disk end and move towards the other end and servicing the requests until it approaches to the other end of the disk. At the end of the movement, the head immediately returns to the beginning of the disk and continue the services.
Consider the following program:
define max 20
define cymax 199
// Initialize and declare the variables.
int i**,** j**,** req**,** ttl_tracks**=** 0**,** cp**,** np**,** cposn**,** nposn**;**
int cyposn**[** max**],** temp**;**
//Input() method is created
void input**()**
{
do
{
//Enter the header position
printf**(** “\n Enter the current header position : ”);
scanf**(** “%d”, &cposn);
}while( cposn**>** cymax || cposn < =0);
printf**(** “\n Enter the %d Requests : ”, req**);**
cyposn**[** 0**]** = cposn**;**
for**(** i**=** 1**;** i**< =req;** i**++)**
scanf**(** “%d”, &cyposn[ i**]);**
}
void CSCAN**()**
{
//Nested for() loop is used to perform swapping
for**(** i**=** 0**;** i**< =req;** i**++)**
{
for**(** j**=** 0**;** j**<** req**-** i**;** j**++)**
{
if**(** cyposn**[** j**]** > cyposn**[** j**+** 1**])**
{
//Swapping performed here.
temp = cyposn**[** j**];**
cyposn**[** j**]** = cyposn**[** j**+** 1**];**
cyposn**[** j**+** 1**]** = temp**;**
}
}
}
cp**=** 0**;**
do
{
//Check if cypon[cp]==cposn
if**(** cyposn**[** cp**]** == cposn**)**
break**;**
cp**++;**
}while( cp**!=** req**);**
printf**(** “\nS.No. Current Position
Next Position Displacement \n”);
printf**(** ”-----------------------------------------------
----------- \n\n”);
i**=** 0**,** j**=** cp**;**
cposn = cyposn**[** cp**];**
do
{
if**(** cposn == cyposn**[** req**])**
{
//Set the values
nposn = 199**;** cp = - 1**;**
}
else
//Increamet the position
nposn = cyposn**[++** cp**];**
printf**(** ” %d\t\t%d\t\t%d\t\t%d\n”,
++ i**,** cposn**,** nposn**,** abs**(** cposn**-** nposn**));**
ttl_tracks += ( abs**(** cposn**-** nposn**));**
cposn = nposn == 199 ? 0 : nposn**;**
}while( nposn != cyposn**[** j**-** 1**])**
printf**(** ”-----------------------------------------------
----------- \n\n”);
printf**(** ” Total Tracks Displaced : %d”, ttl_tracks**);**
}
Main() method called here.
int main**()**
{
do
{
printf**(** “\n Enter the number of requests : ”);
scanf**(** “%d”, &req);
}while( req**>** max || req < =0);
//Calling input() method
input**();**
//Calling CSCAN()
CSCAN**();**
getch**();**
}
Step-6
Sample Output:
Enter the number of requests : 6
Enter the current header position : 45
Enter the 6 Requests : 56
88
90
23
77
88
S.No. Current Position Next Position Displacement
----------------------------------------------------------
1 45 56 11
2 56 77 21
3 77 88 11
4 88 88 0
5 88 90 2
6 90 199 109
7 0 23 23
----------------------------------------------------------
Total Tracks Displaced : 177
Step-7
Consider the following program which is used to performLOOK****disk scheduling:
define max 20
define cymax 199
int i**,** j**,** req**,** ttl_tracks**=** 0**,** cp**,** np**,** cposn**,** nposn**;**
int cyposn**[** max**],** temp**;**
//input() function is created.
void input**()**
{
//Enter the current header position.
printf**(** “\n Enter the current header position : ”);
scanf**(** “%d”, &cposn);
//Enter the IO request.
printf**(** “\n Enter the %d I/O Requests : ”, req**);**
cyposn**[** 0**]** = cposn**;**
for**(** i**=** 1**;** i**< =req;** i**++)**
scanf**(** “%d”, &cyposn[ i**]);**
}
// Look() method is created.
void LOOK**()**
{
int ind = 0**;**
//Nested for() loop is used to perform swapping.
for**(** i**=** 0**;** i**< =req;** i**++)**
{
for**(** j**=** 0**;** j**<** req**-** i**;** j**++)**
{
if**(** cyposn**[** j**]** > cyposn**[** j**+** 1**])**
{
//Swapping
temp = cyposn**[** j**];**
cyposn**[** j**]** = cyposn**[** j**+** 1**];**
cyposn**[** j**+** 1**]** = temp**;**
}
}
}
cp**=** 0**;**
do
{
//Check if cyposn[cp]==cposn
if**(** cyposn**[** cp**]** == cposn**)**
break**;**
cp**++;**
}while( cp**!=** req**);**
int tmp = cp**;**
printf**(** “\nS.No. Current Position Next Position
Displacement \n”);
printf**(** ”----------------------------------------
---------------- \n\n”);
i**=** 0**;**
cposn = cyposn**[** cp**];**
do
{
if**(** ind == 0**)**
{
if**(** cp == 0**)**
{
//assignment
cp = tmp**;**
nposn = cyposn**[++** cp**];** ind = 1**;**
}
else
nposn = cyposn**[—** cp**];**
}
else
nposn = cyposn**[++** cp**];**
printf**(** ” %d\t\t%d\t\t%d\t\t%d\n”,
++ i**,** cposn**,** nposn**,** abs**(** cposn**-** nposn**));**
ttl_tracks += ( abs**(** cposn**-** nposn**));**
cposn = nposn**;**
}while( nposn**!=** cyposn**[** req**]);**
printf**(** ”----------------------------------
------------------------ \n\n”);
printf**(** ” Total Tracks Displaced : %d”, ttl_tracks**);**
}
//Main() method is called.
int main**()**
{
do
{
//Enter the number of request.
printf**(** “\n Enter the number of requests : ”);
scanf**(** “%d”, &req);
}while( req**>** max || req < =0);
//input() method called.
input**();**
//Look() method is called here.
LOOK**();**
getch**();**
}
Step-8
Sample Output:
Enter the number of requests : 6
Enter the current header position : 44
Enter the 6 I/O Requests : 23
99
76
56
87
33
S.No. Current Position Next Position Displacement
----------------------------------------------------------
1 44 33 11
2 33 23 10
3 23 56 33
4 56 76 20
5 76 87 11
6 87 99 12
----------------------------------------------------------
Total Tracks Displaced : 97
Consider the following program which is performedC-LOOK disk scheduling:
//Initialize and declare the variables.
int cymax**,** i**,** j**,** req**,** ttl_tracks**=** 0**,** cp**,** np**,** cposn**,** nposn**;**
int cyposn**[** 20**],** ind**[** 20**],** temp**;**
//CLOOK() function is used to perform CLOOK Scheduling.
void CLOOK**()**
{
int t**;**
//Nested for() loop is used to perform swapping
for**(** i**=** 0**;** i**< =req;** i**++)**
{
for**(** j**=** 0**;** j**<** req**-** i**;** j**++)**
{
if**(** cyposn**[** j**]** > cyposn**[** j**+** 1**])**
{
//Swapping
temp = cyposn**[** j**];**
cyposn**[** j**]** = cyposn**[** j**+** 1**];**
cyposn**[** j**+** 1**]** = temp**;**
}
}
}
cp**=** 0**;**
do
{
//Check if cyposn[cp]==cposn
if**(** cyposn**[** cp**]** == cposn**)**
break**;**
cp**++;**
}while( cp**!=** req**);**
printf**(** “\nS.No. Current Position Next Position
Displacement \n”);
i**=** 0**,** j**=** cp**;**
cposn = cyposn**[** cp**];**
do
{
if**(** cp == req**)**
{
nposn = cyposn**[** 0**];** cp = 0**;**
}
else
nposn = cyposn**[++** cp**];**
t**=** abs**(** cposn**-** nposn**);**
printf**(** “%d\t\t%d\t\t%d\t\t%d\n”,
++ i**,** cposn**,** nposn**,** t**);**
ttl_tracks += ( abs**(** cposn**-** nposn**));**
cposn = nposn == cyposn**[** req**]** ? cyposn**[** 0**]** : nposn ;
}while( nposn != cyposn**[** j**-** 1**]);**
printf**(** “total track displaced=%d”, ttl_tracks**);**
}
//Main() method is called.
int main**()**
{
//Enter the number of request.
printf**(** “Enter the number of requests”);
scanf**(** “%d”, &req);
//Enter the maximum range of request.
printf**(** “Enter the maximum range of requests”);
scanf**(** “%d”, &cymax);
//Emter the current head position
printf**(** “Enter current Head position”);
scanf**(** “%d”, &cposn);
//Enter the request
printf**(** “Enter th requests”);
cyposn**[** 0**]** = cposn**;**
for**(** i**=** 1**;** i**< =req;** i**++)**
scanf**(** “%d”, &cyposn[ i**]);**
//CLLOK is called here.
CLOOK**();**
system**(** “pause”);
return 0**;**
}
Sample Output:
Enter the number of requests6
Enter the maximum range of requests100
Enter current Head position0
Enter th requests24
62
38
12
80
25
S.No. Current Position Next Position Displacement
1 0 12 12
2 12 24 12
3 24 25 1
4 25 38 13
5 38 62 24
6 62 80 18
7 0 0 0
total track displaced=80